
A Call for Better Risk Modelling
Published:
TL;DR: The EU’s Code of Practice (CoP) mandates AI companies to conduct state-of-the-art Risk Modelling. However, the current SoTA is has severe flaws. By creating risk models and improving methodology, we can enhance the quality of risk management performed by AI companies. This is a neglected area, hence we encourage more people in AI Safety to work on it. Work on Risk Modelling is urgent because the CoP is to be enforced starting in 9 months (Aug, 2, 2026).
This post was co-authored with Charbel-Raphaël Segerie from CeSIA and originally published on LessWrong.
The EU’s Code of Practice requires SoTA Risk Management practices.
The AI Act and its CoP is currently the most comprehensive regulation to prevent catastrophic AI risks. Many Frontier AI companies have signed the EU’s Code of Practice (CoP), and the AI Office, which enforces it, is staffed with competent personnel. The CoP requires companies to conduct risk management with respect to threats such as CBRN capabilities, Loss of Control, Cyber Offense, or Harmful Manipulation.
The code often refers to “state-of-the-art” and “appropriate” methods, instead of mandating specific Risk Management Practices. This opens a possibility for civil society and academics to raise the bar for AI companies by improving the state-of-the-art and building consensus on which strategies are appropriate.
In particular, the CoP requests a SoTA Safety and Security Framework (Commitment 1), risk modeling methods (Measure 3.3), model evaluations (Measure 3.2), and appropriate safety mitigations (Commitment 5).
Risk modeling seems to be the highest leverage
Definition. From Campos et al 2025:
Risk modeling is the systematic process of analyzing how identified risks could materialize into concrete harms. This involves creating detailed step-by-step scenarios of risk pathways that can be used to estimate probabilities and inform mitigation strategies.
The other requested practices in the CoP seem to be less neglected or have less leverage:
- Safety and Security Framework: Companies should (and are) already doing this. The SoTA is already decent (e.g. Anthropic’s RSP) and outsiders have less influence here.
- Model evaluations: Already a somewhat popular area of research. Additionally, risk modeling should inform the design of our evaluations.
- Appropriate safety mitigations: Not that neglected, as it’s an active area of research. The SoTA is already decent wrt safeguards and monitoring.
In comparison, risk modeling enables:
- Setting reasonable thresholds and red lines: If we obtain a reasonable estimate of quantitative risks, we can establish thresholds
- … and assess whether the mitigations are appropriate or not. Risk Models help us define more clearly what is “appropriate”.
- Guides eval design: By identifying key tasks and enabling capabilities, you are then able to create more relevant evals
- Advocacy tool: Risk Models allow us to make claims such as: “Publishing this model will kill 10k people in expectation because of engineered pandemics”. This clearly communicates the level of risk. Additionally, translating vague dangers into specific Risk Models makes them accessible to companies and the EU AI Office. Warning of vague hazards is not enough; we need to specify risks formally.
- Improve Clarity: Currently, there is a substantial level of uncertainty regarding the risks, with some experts and superforecasters disagreeing entirely (see this survey, for example). Risk Models can help integrate and bring together varying opinions and thus provide more clarity on the risks.
Risk modeling is very neglected. There is little public work available on Risk Modelling for AI12. Some notable work includes threat models on LLM-assisted spear phishing campaigns or the Replication of Rogue AI Agents. However, many essential risks don’t have a solid canonical risk model yet (see next section for examples), and most risk models can be harshly criticised. As a result, AI Risk Modelling lags far behind other fields such as nuclear engineering or aviation, where rigorous Probabilistic Risk Assessment, Fault Tree Analysis, and standardised units of risk are common.
This is an opportunity! There is a strong chance that by doing 3rd party research, you will influence what companies use in their reporting. If you improve the SoTA, in theory, the CoP requires companies to use your paper. Additionally, according to the CoP, companies should consider publicly accessible information, which includes your risk models. If companies don’t comply with this, the AI Office should block their model release on the EU market. Lastly, we think there are highly tractable projects for improving Risk Modelling (see next section).
Some counterarguments against prioritising risk modelling:
- Risk Modelling is complex for Black Swan events. They work best in areas where we have failure data. But for x-risk type threats, there is no data. - However, we expect current AI progress to remain continuous. Thus, we will still be able to measure key capabilities, map how they influence risk models, and thus manage emerging risks better.
- Perhaps the companies already have robust threat models in place internally? - Public Risk Models are open to community feedback. Additionally, companies don’t have strong incentives to produce more/better Risk Models, which makes it likely there is additional useful work for outsiders.
- Publishing threat models could be an information hazard by highlighting ways for bad actors to cause damage.
- We face deep uncertainty on how to estimate the risks. For example, experts and superforecasters disagree by 2 OOM here. This might be fundamentally difficult to handle methodologically.
But overall, we think it is very worthwhile to work on Risk Modelling.
What can be done?
Obviously, creating more risk models. Currently, only a tiny space of threats posed by Frontier AI is covered by Risk Models. Many risks have been discussed for years, yet nobody has rigorously modeled them. Some examples include:
- Rogue AIs escaping internal deployment
- Using AIs for wide-scale political manipulation
- Using AIs to carry out CBRN attacks (there is a nascent risk model literature for biological risks, but still very insufficient)
- AIs causing psychosis
Translating vague threat models on LessWrong to formal risks models. This makes the risks accessible to the AI Office; A concrete way to do this is presented in Appendix 1.
Improving methodology. The current SOTA Risk Modelling methodology is nascent. Examples of methodological improvements are UK AISI’s structured protocol for Expert Elicitation, CARMA’s framework for Probabilistic Risk Assessment, or Safer AI’s research combining benchmark scores with expert elicitation. Further work is necessary to make risk modelling more scalable, navigate widely diverging expert opinions, appropriately include uncertainty, or employ principled methods of forecasting damages. (There are many other possible improvements.) It might be especially fruitful to study practices and frameworks from fields with more mature Risk Modeling, such as aviation or healthcare, including Fault Tree Analysis, Bow-Tie Analysis, or Key Risk Indicators.
Building consensus and coordination. If the scientific community can find agreement on which Risk Models and methodologies are SOTA, the AI Office could force companies to apply these. Such coordination could look like organising workshops or conducting surveys of experts to determine which risk models and methodologies are regarded as best. For example, helping the field converge on which evidence should be used in Risk Models (e.g., uplift studies, capability benchmarks, expert judgements).
If you are interested, you can complete this form to join a Slack channel to coordinate on this!
Appendix
An example of what Risk Modeling can look like in practice
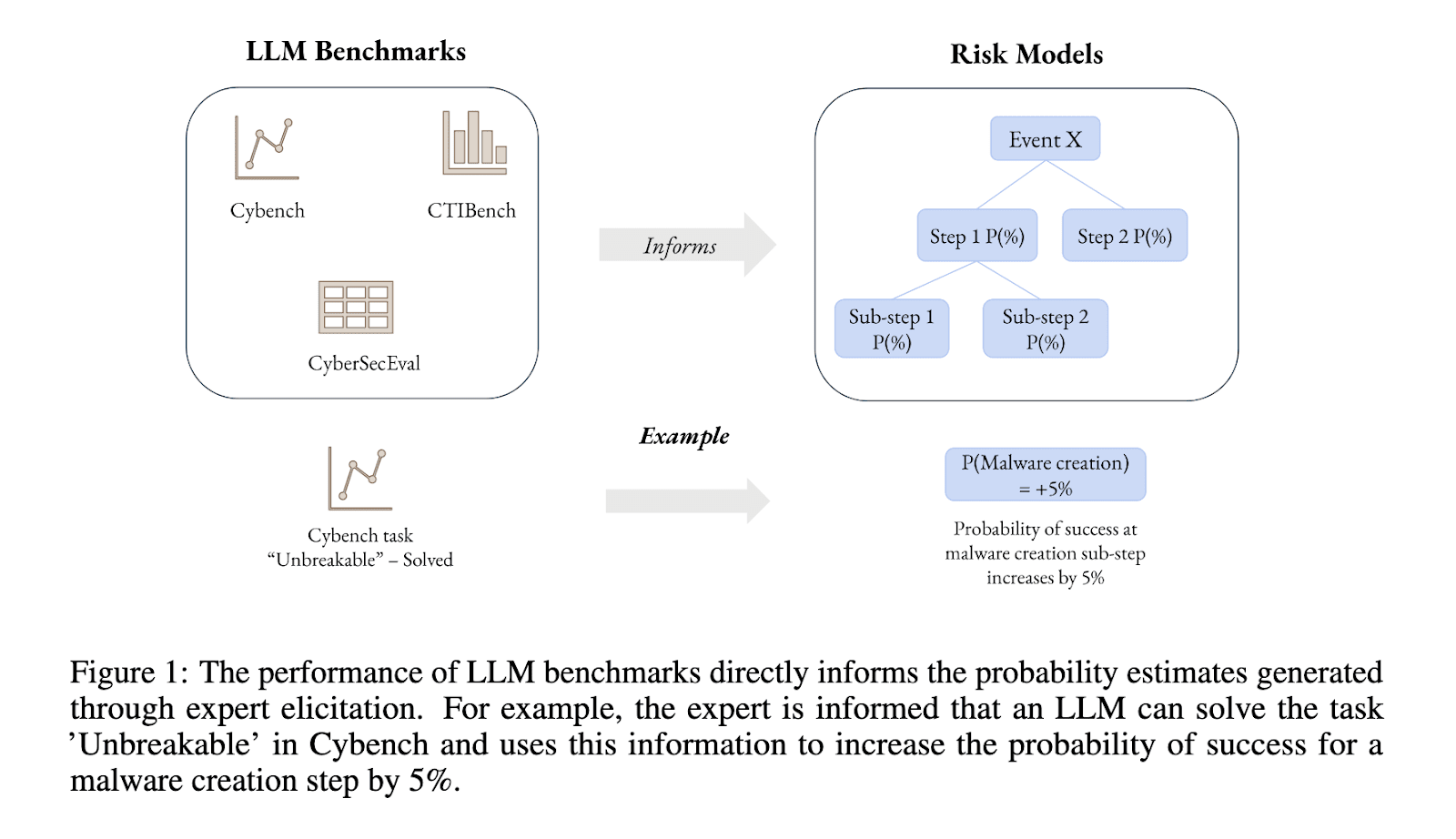

Mapping AI Benchmark Data to Quantitative Risk Estimates Through Expert Elicitation (Campos, 2025)
How do they go from a given level of capability to a level of risk:
- They take a few LLM benchmarks in cyber.
- Experts are asked to estimate the probability of a model succeeding on a task based on its benchmark score. E.g., given that the model can solve the task “Unbreakable” in Cybanch, how likely is it that the model can complete the malware creation step? Experts’ opinions are complemented with additional LLM-as-a-forecaster predictions.
- This approach is employed using multiple benchmarks and steps.
References and Resources
Some orgs doing work on this include:
- CARMA does Probabilistic Risk Assessment
- METR has done some work on threat modelling.
- SaferAI is pushing Risk Modelling in cyber.
Some relevant papers:
- A Frontier AI Risk Management Framework: Bridging the Gap Between Current AI Practices and Established Risk Management
- Mapping AI Benchmark Data to Quantitative Risk Estimates Through Expert Elicitation
- The Rogue Replication Threat Model
- LLM Cyber Evaluations Don’t Capture Real-World Risk
- Probabilistic Risk Assessment
- A structured protocol for elicitation experiments
Work done at the international SC-WOP workshop, 2025.